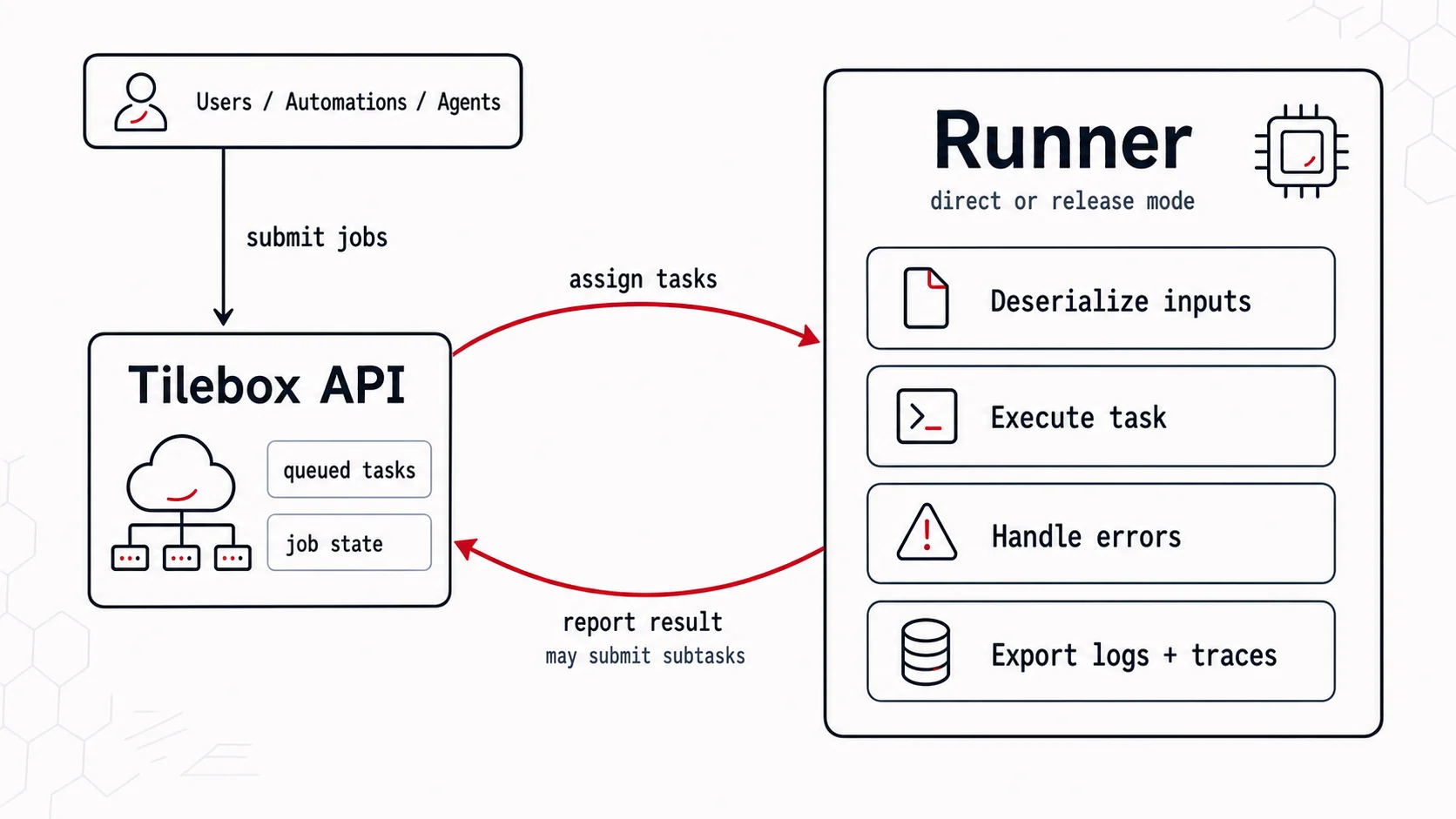
Runner modes
Tilebox supports two runner modes. A release runner is started with the Tilebox CLI, loads workflow releases deployed to its cluster, and reacts to updated cluster deployments while it runs. A direct runner is a standalone script, service, or binary that uses the Tilebox SDK to connect to the API and register tasks directly. Release runners still run in an environment you control, but the workflow code they execute is selected through cluster deployments. This separates compute operations from workflow release rollout. Direct runners are scaled and rolled out by your own infrastructure.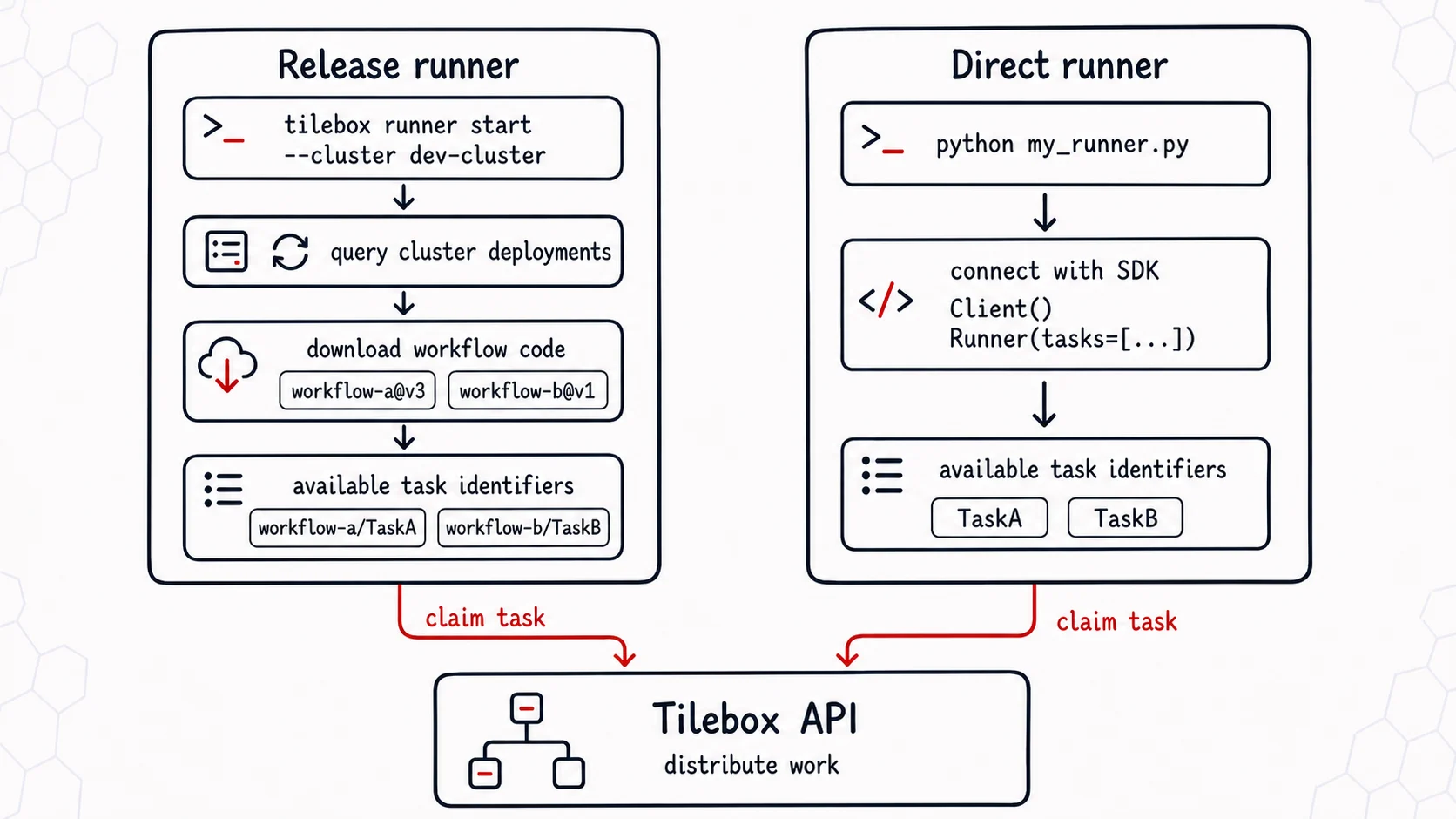
Release runners
A release runner runs Python workflow releases deployed to a cluster. Start it with the Tilebox CLI:Release runners currently only support Python workflow projects. The Tilebox CLI invokes the Python runner environment from the published release artifact using
uv.Direct runners
A direct runner connects to the Tilebox API from your own code. Use it when you want full control over the process, deployment environment, dependencies, startup behavior, and scaling. You are responsible for deploying the script or binary, keeping it running, rolling out code changes, and rolling back when needed. Define aRunner instance once and connect it to a Client during startup.
Task selection
For a runner to pick up a submitted task, these conditions must match:- The task was submitted to the same cluster as the runner.
- The runner advertises a task identifier with the same name and a compatible version.
- The task must be in
QUEUEDstate, its dependencies are met, and its maximum retries aren’t exhausted.
Parallelism
Start multiple runner processes to execute tasks in parallel. Each runner process claims and executes tasks independently. You can run multiple release runners, multiple direct runners, or a mix of both in the same cluster. This increases parallelism and helps handle large workloads. To test this, run multiple instances of the runner script in different terminal windows on your local machine, or use the CLI built-inparallel subcommand to start multiple runners in parallel.
Scaling
One key benefit of this runner architecture is the ability to scale even while workflows are executing. You can start new runners at any time, and they can immediately pick up queued tasks to execute. You do not need an entire processing cluster available at the start of a workflow, because you can start and stop more runners as needed. This is particularly beneficial in cloud environments, where runners can be automatically started and stopped based on current workload, measured by metrics such as CPU usage. Here’s an example scenario:- A single runner process is actively waiting for work in a cloud environment.
- A large workload is submitted to the workflow orchestrator, resulting in the runner picking up the first task.
- The first task creates new sub-tasks for processing, which the runner also picks up.
- As the workload increases, the runner’s CPU usage rises, triggering the cloud environment to automatically start up new runner instances.
- Newly started runners begin executing queued tasks, distributing the workload among all available runners.
- Once the workload decreases, the cloud environment automatically stops some runners.
- The remaining work continues while runner instances are scaled back down, until everything is done.
- Only a single runner remains idle until new tasks arrive.
In a future release, configuration options for scaling runners based on custom metrics (for example the number of queued tasks) are planned.
Distributed Execution
Runners can be distributed across different compute environments. For instance, some data stored on-premise may need pre-processing, while further processing occurs in the cloud. A job might involve tasks that filter relevant on-premise data and publish it to the cloud, and other tasks that read data from the cloud and process it. In such scenarios, one runner can run on-premise and another in a cloud environment, resulting in them effectively collaborating on the same job. Another advantage of distributed runners is executing workflows that require specific hardware for certain tasks. For example, one task might need a GPU, while another requires extensive memory. Here’s an example of a distributed workflow:DownloadData task, while the second picks up the ProcessData task.
The DistributedWorkflow does not require specific hardware, so it can be registered with both runners and executed by either one.
- download_runner.py
- gpu_runner.py
download_runner.py and gpu_runner.py are started, in parallel, on different machines with the required hardware for each. When DistributedWorkflow is submitted, it executes on one of the two runners, and it’s submitted sub-tasks are handled by the appropriate runner.
In this case, since ProcessData depends on DownloadData, the GPU runner remains idle until the download completion, then picks up the processing task.
Task Failures
If an unhandled exception occurs during task execution, the runner captures it and reports it back to the workflow orchestrator. The orchestrator then marks the task as failed, leading to job cancellation to prevent further tasks of the same job-that may not be relevant anymore-from being executed. A task failure does not result in losing all previous work done by the job. If the failure is fixable—by fixing a bug in a task implementation, ensuring the task has necessary resources, or simply retrying it due to a flaky network connection—it may be worth retrying the job. When retrying a job, all failed tasks are added back to the queue, allowing a runner to potentially execute them. If execution then succeeds, the job continues smoothly. Otherwise, the task will remain marked as failed and can be retried again if desired. For a release runner, publish a compatible fixed release and deploy it to the same cluster before retrying. For a direct runner, deploy the fixed script or binary before retrying. Keep task identifiers and input schemas compatible when you want an existing failed job to resume from the point of failure.Task idempotency
Since a task may be retried, it’s possible that a task is executed more than once. Depending on where in the execution of the task it failed, it may have already performed some side effects, such as writing to a database, or sending a message to a queue. Because of that it’s crucial to ensure that tasks are idempotent. Idempotent tasks can be executed multiple times without altering the outcome beyond the first successful execution. A special case of idempotency involves submitting sub-tasks. After a task callscontext.submit_subtask and then fails and is retried, those submitted sub-tasks of an earlier failed execution are automatically removed, ensuring that they can be safely submitted again when the task is retried.